Appendix
GPU 가상화를 통한 컨테이너 별 GPU 분할 할당
Backend.AI 는 하나의 물리 GPU 를 여러 개로 분할해서 여러 사용자가 나누어 사용할 수 있는 가상화 기술을 지원하고 있습니다. 따라서, GPU 연산 소요가 크지 않은 작업을 수행하고자 할 경우에는 GPU 의 일부만 할당하여 연산 세션을 생성할 수 있습니다. 1 fGPU 가 실제로 할당하는 GPU 자원의 양은 관리자 설정에 따라 시스템 별로 다양할 수 있습니다. 예를 들어, 관리자가 하나의 GPU 를 다섯 조각으로 분할 설정한 경우, 5 fGPU 가 1 물리 GPU, 또는 1 fGPU 가 0.2 물리 GPU 를 뜻합니다. 이 때 1 fGPU 를 설정하여 연산 세션을 생성하면, 그 세션에서는 0.2 물리 GPU 에 해당하는 SM(streaming multiprocessor) 과 GPU 메모리를 활용할 수 있습니다.
이번에는 GPU 를 일부만 할당하여 연산 세션을 생성한 후 연산 컨테이너 내부에서 인식하는 GPU 가 정말 물리 GPU 의 일부분인지 확인 해보도록 하겠습니다.
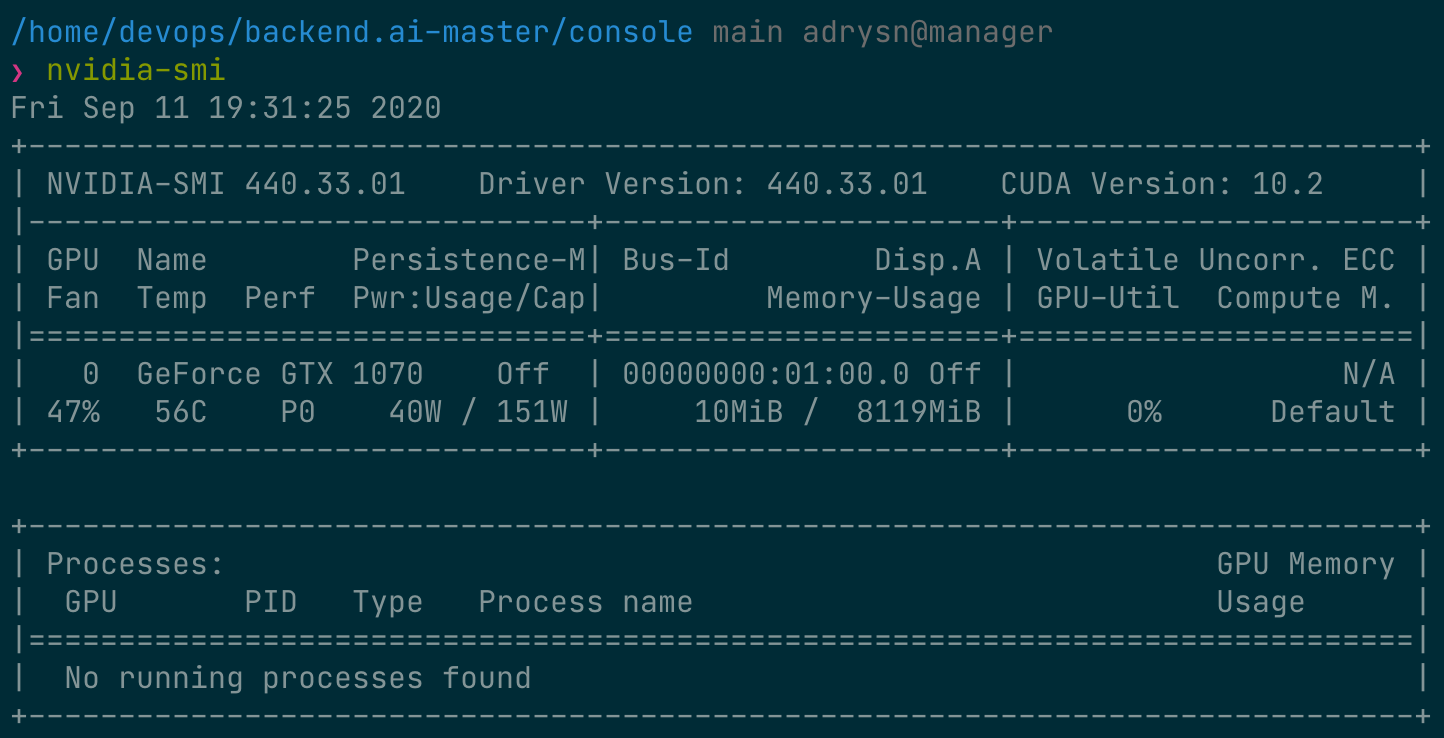
먼저 호스트 노드에 장착되어 있는 물리 GPU 의 종류와 메모리 용량 등의 정보를 확인 해보겠습니다. 이 가이드를 작성하면서 사용한 GPU 노드에는 다음과 같이 8 GB 메모리의 GPU 가 장착되어 있습니다. 그리고 관리자 설정을 통해 1 fGPU 를 0.5 개의 물리 GPU(또는 1 개의 물리 GPU 가 2 fGPU) 에 해당하는 양으로 설정하였습니다.
이제 Sessions 페이지로 이동하여 다음과 같이 0.5 개의 fGPU 를 할당하여 연산 세션을 생성해봅시다.
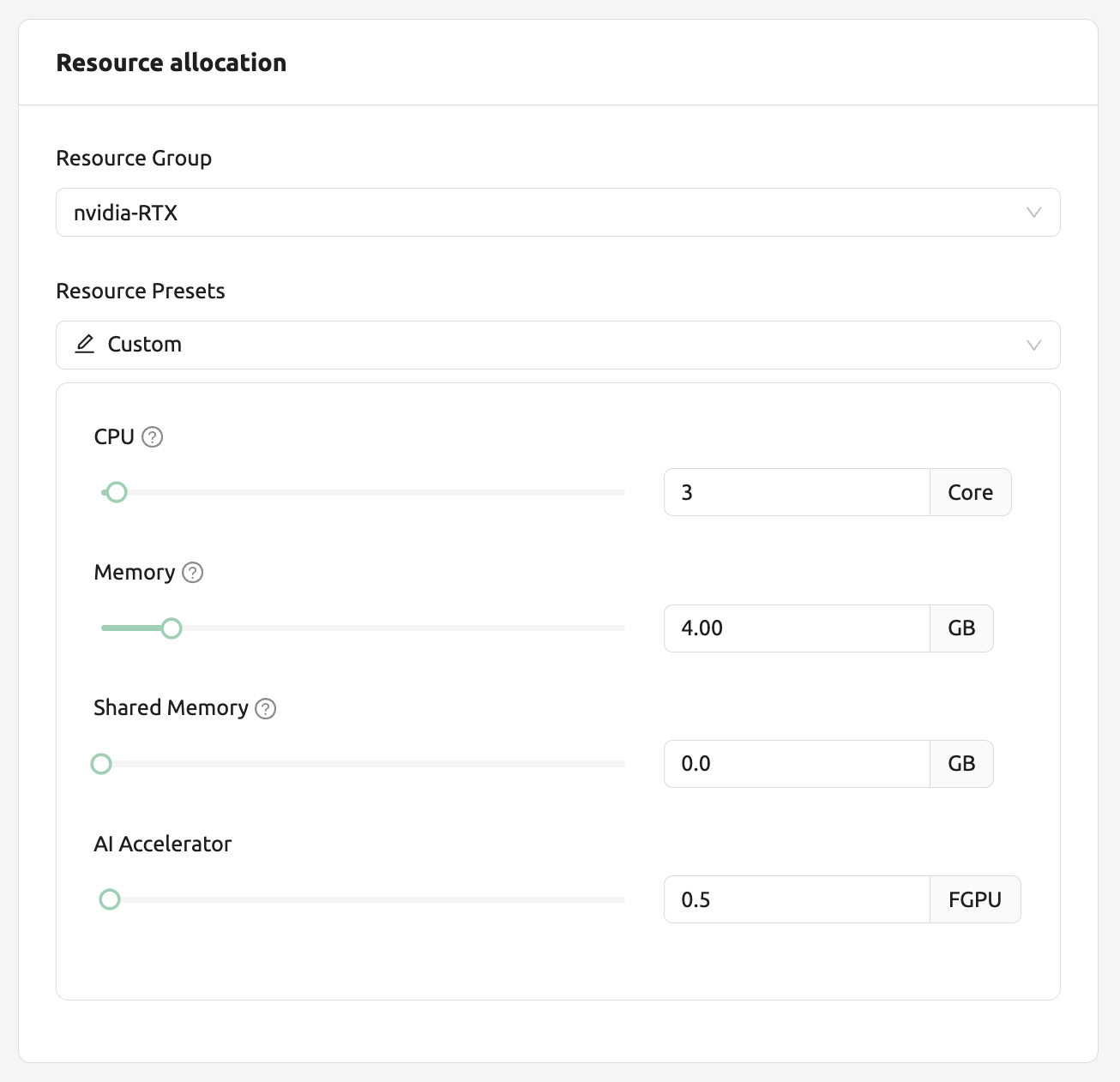
연산 세션 리스트의 AI Accelerator 열에서 0.5 의 fGPU 가 할당된 것을 확인할 수 있습니다.

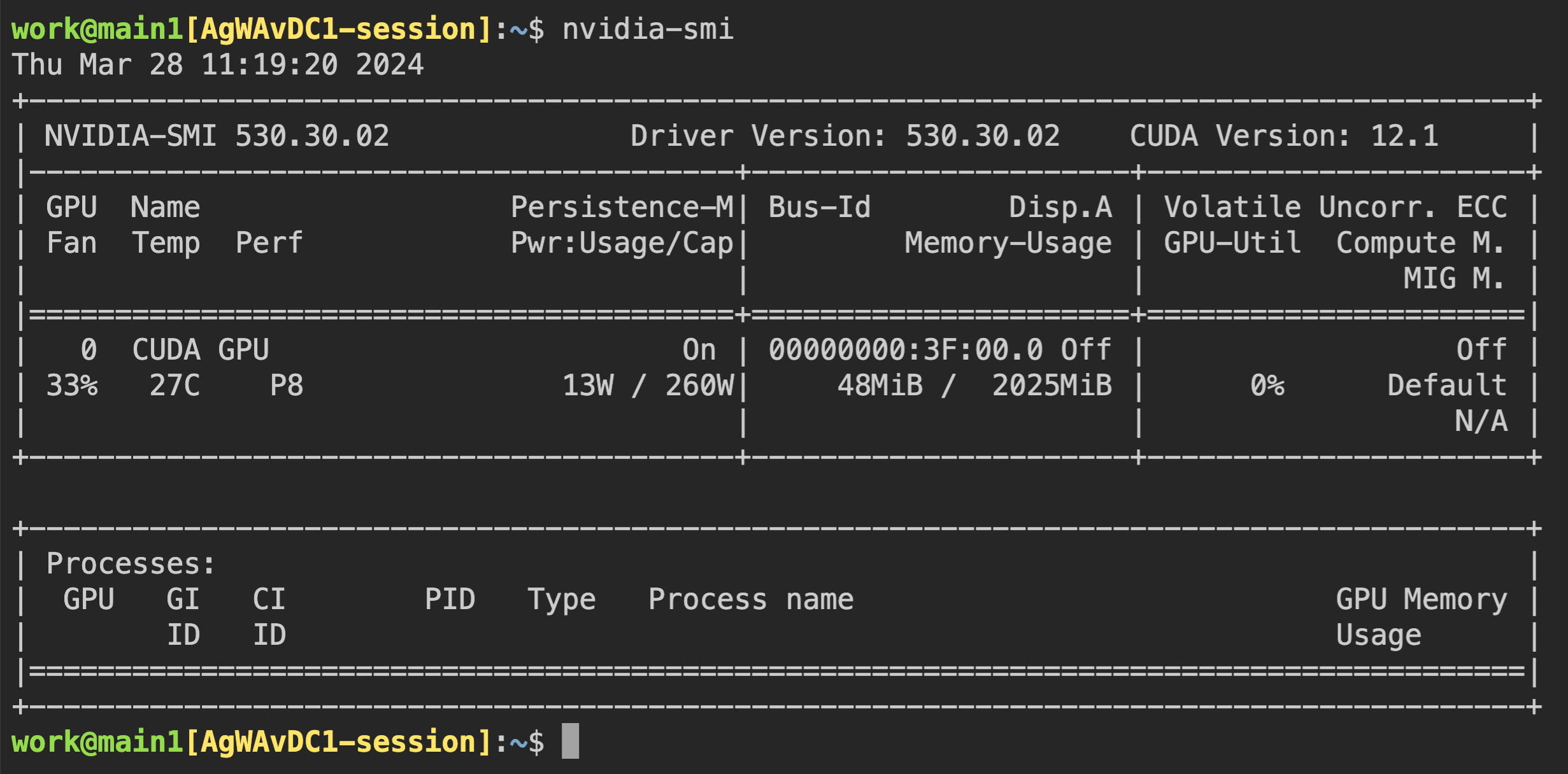
이제 컨테이너에 직접 연결하여 할당 된 GPU 메모리가 실제로 0.5 단위 (~ 2GB)와 동일한지 확인하겠습니다. 웹 터미널을 띄웁니다. 터미널이 나타나면 nvidia-smi 명령을 실행합니다. 다음 그림에서 볼 수 있듯이 약 2GB의 GPU 메모리가 할당 되었음을 알 수 있습니다. 이는 물리적 GPU가 실제로 네 부분으로 나뉘어 이 연산 세션에 할당되었음을 보여 줍니다. 이는 PCI 패스스루(passthrough0와 같은 방식으로는 불가능합니다.
이번에는 Jupyter Notebook 을 띄워서 간단한 ML 학습 코드를 실행해보겠습니다.
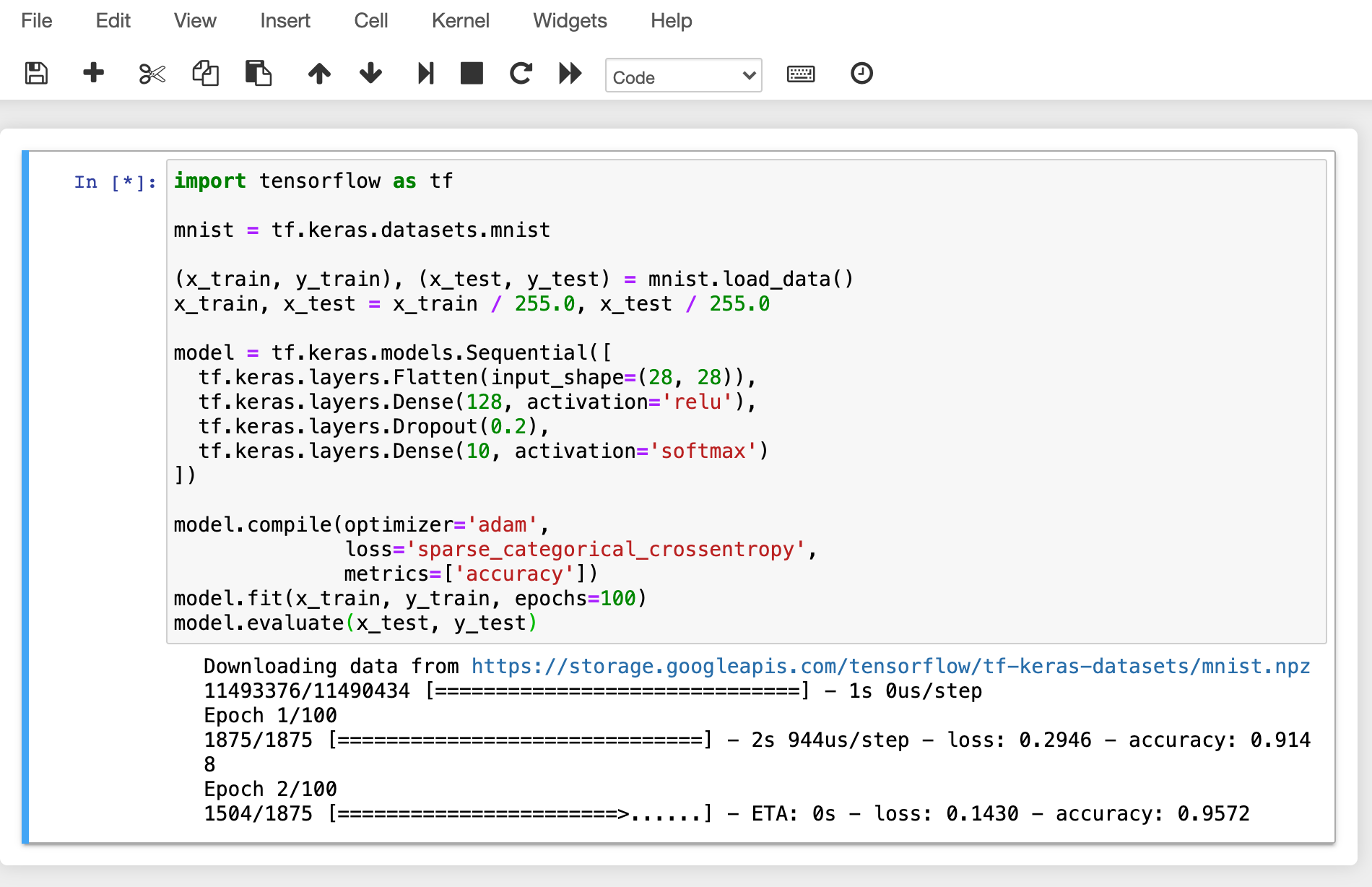
학습이 진행되는 동안 GPU 호스트 노드의 쉘로 접속해서 nvidia-smi 명령을 실행합니다. 다음과 같이 하나의 GPU 사용 프로세스가 있고 이 프로세스는 물리 GPU의 약 25% 에 해당 하는 자원을 점유중임을 알 수 있습니다. (GPU 점유량은 학습 코드와 GPU 모델에 따라 크게 다를 수 있습니다.)
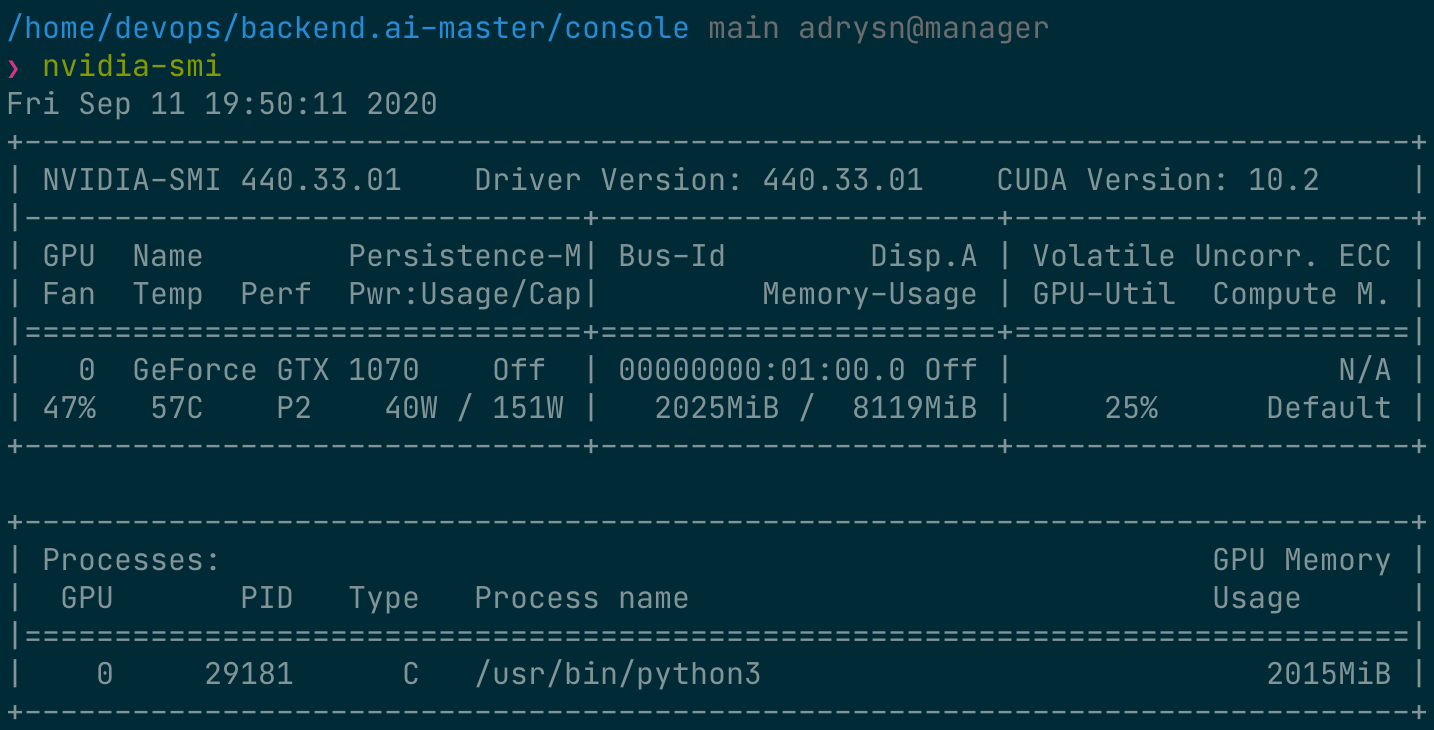
또는, 아까 띄워둔 웹 터미널에서 nvidia-smi 명령을 내려 컨테이너 내부에서 인식하는 GPU 사용 내역을 조회해 보는 것도 가능합니다.
GUI 를 통한 자원 모니터링 및 스케줄링 자동화
Backend.AI 서버는 자체 개발한 작업 스케줄러를 내장하고 있습니다. 자동으로 모든 워커 (worker) 노드의 자원 상태를 확인하여 사용자의 자원 요청에 맞는 워커로 연산 세션 생성 요청을 위임 합니다. 또한, 자원이 부족할 경우에는 일단 작업 큐에 사용자의 연산 세션 생성 요청을 대기 (pending) 시키고 나중에 자원이 다시 가용 상태가 되면 대기 요청을 활성화 해서 연산 세션 생성 작업을 수행하게 됩니다.
사용자 Web-UI에서 간단한 방법으로 작업 스케줄러의 작동을 확인할 수 있습니다. GPU 호스트가 최대 2 단위의 fGPU를 할당 할 수 있는 경우, 1 단위의 fGPU 할당을 요청하는 3 개의 연산 세션을 동시에 생성해 보겠습니다. 세션 시작 대화 상자의 사용자 지정 할당 패널에는 GPU 및 세션 슬라이더가 있습니다. Sessions에서 1보다 큰 값을 지정하고 LAUNCH 버튼을 클릭하면 여러 개의 세션이 동시에 생성됩니다. GPU와 Sessions을 각각 1과 3으로 설정하겠습니다. 이는 fGPU가 2 단위밖에 없는 상황에서 총 3 단위의 fGPU를 요청하는 상황입니다.
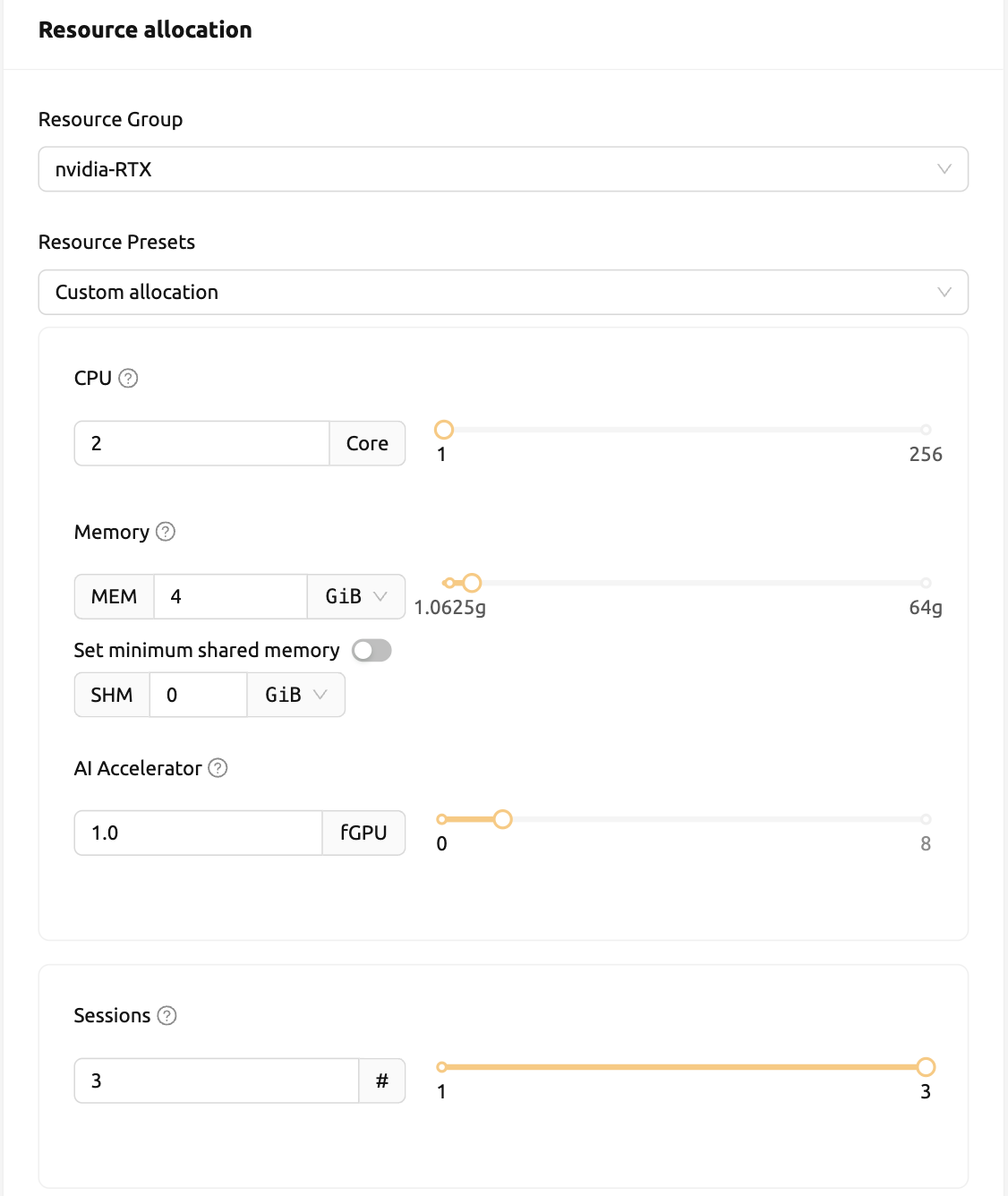
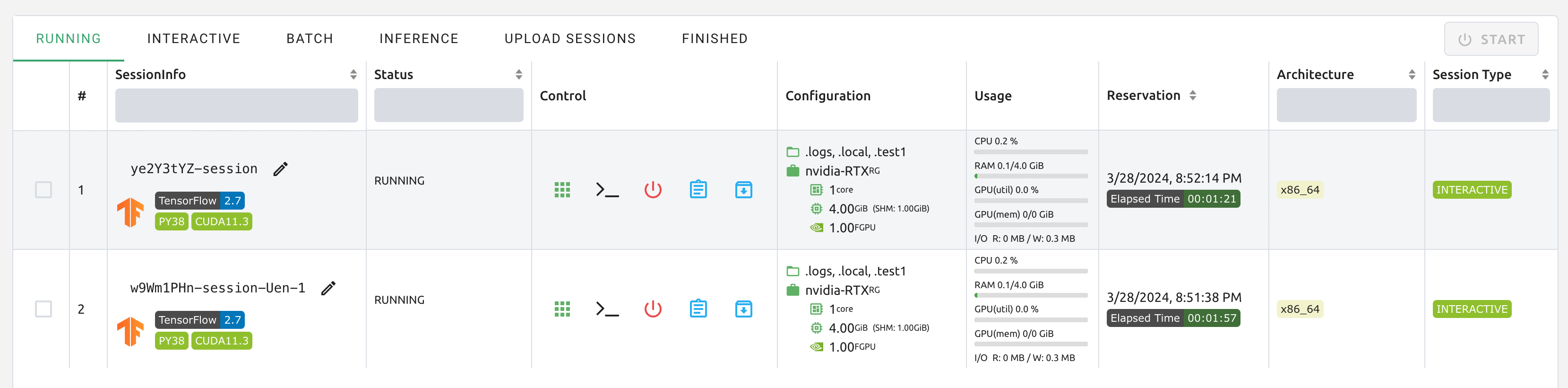
잠시 기다리면 세 개의 연산 세션이 나타납니다. 상태 패널을 자세히 살펴보면 세 개의 연산 세션 중 두 개는 RUNNING 상태에 있지만 다른 연산 세션은 PENDING 상태로 남아 있음을 알 수 있습니다. 이 PENDING 세션은 작업 대기열에만 등록되며 GPU 자원 부족으로 인해 실제로 컨테이너 할당을 받지 못했습니다.

이제 RUNNING 상태의 세션 두 개 중 하나를 삭제해보겠습니다. 그러면 PENDING 상태의 연산 세션은 곧 작업 스케줄러에 의해 자원을 할당 받고 RUNNING 상태로 변환되는 것을 볼 수 있습니다. 이처럼, 작업 스케줄러는 작업 큐를 활용해 사용자의 연산 세션 요청을 간직하고 있다가 가용 자원이 있을 때 자동으로 요청을 처리하게 됩니다.
Multi-version 머신러닝 컨테이너 지원
Backend.AI 는 다양한 ML 및 HPC 커널 이미지를 사전 빌드하여 제공합니다. 따라서, 사용자는 패키지 설치를 하지 않더라도 주요 라이브러리 및 패키지를 즉시 활용할 수 있습니다. 여기서는 다종 ML 라이브러리의 여러 버전을 즉시 활용하는 예제를 진행합니다.
Sessions 페이지로 이동하여 연산 세션 생성 다이얼로그를 엽니다. Backend.AI에서는 설치 환경에 따른 다양한 커널 이미지를 제공합니다.
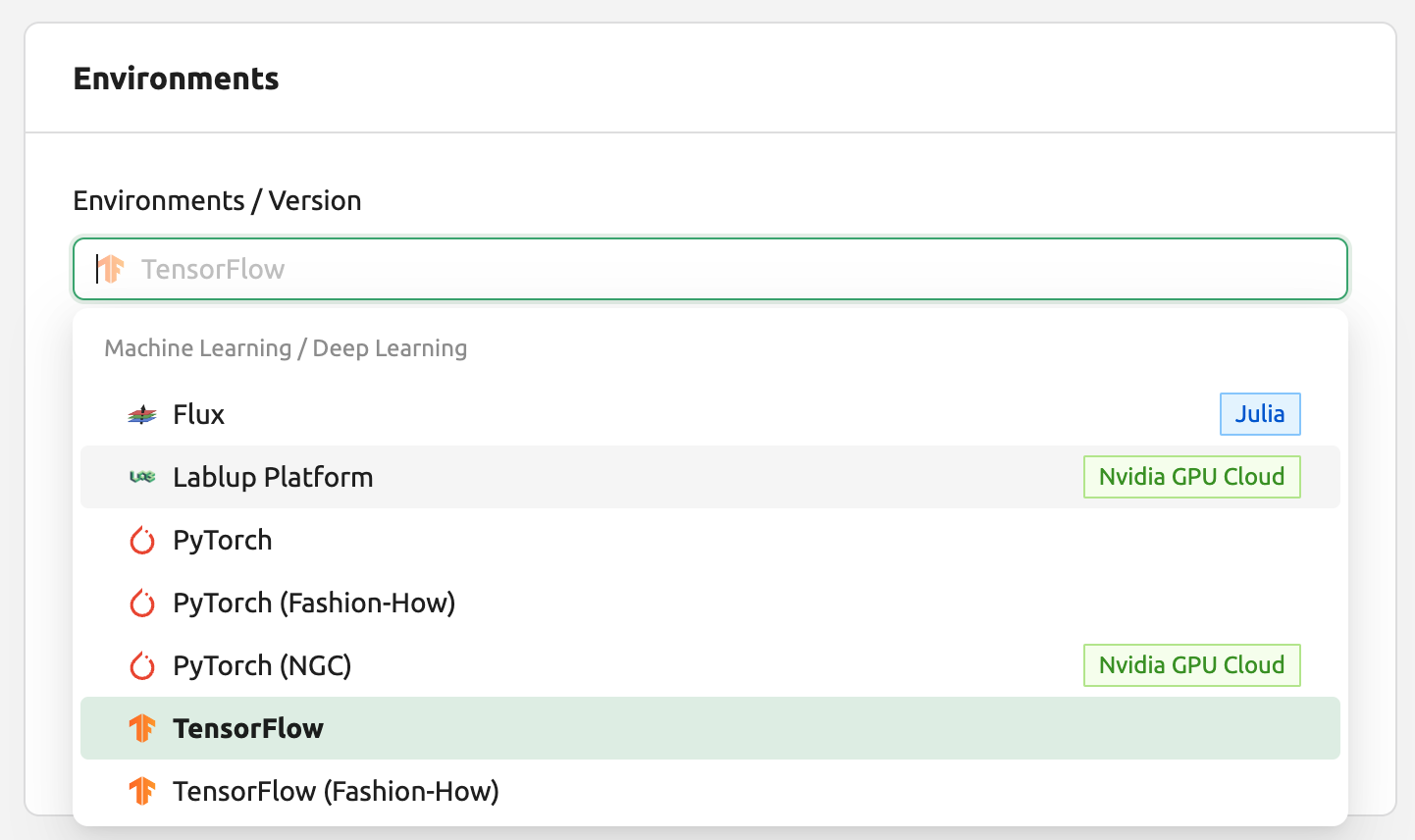
여기서는 TensorFlow 2.3 환경을 선택하고 세션을 생성해 보았습니다.
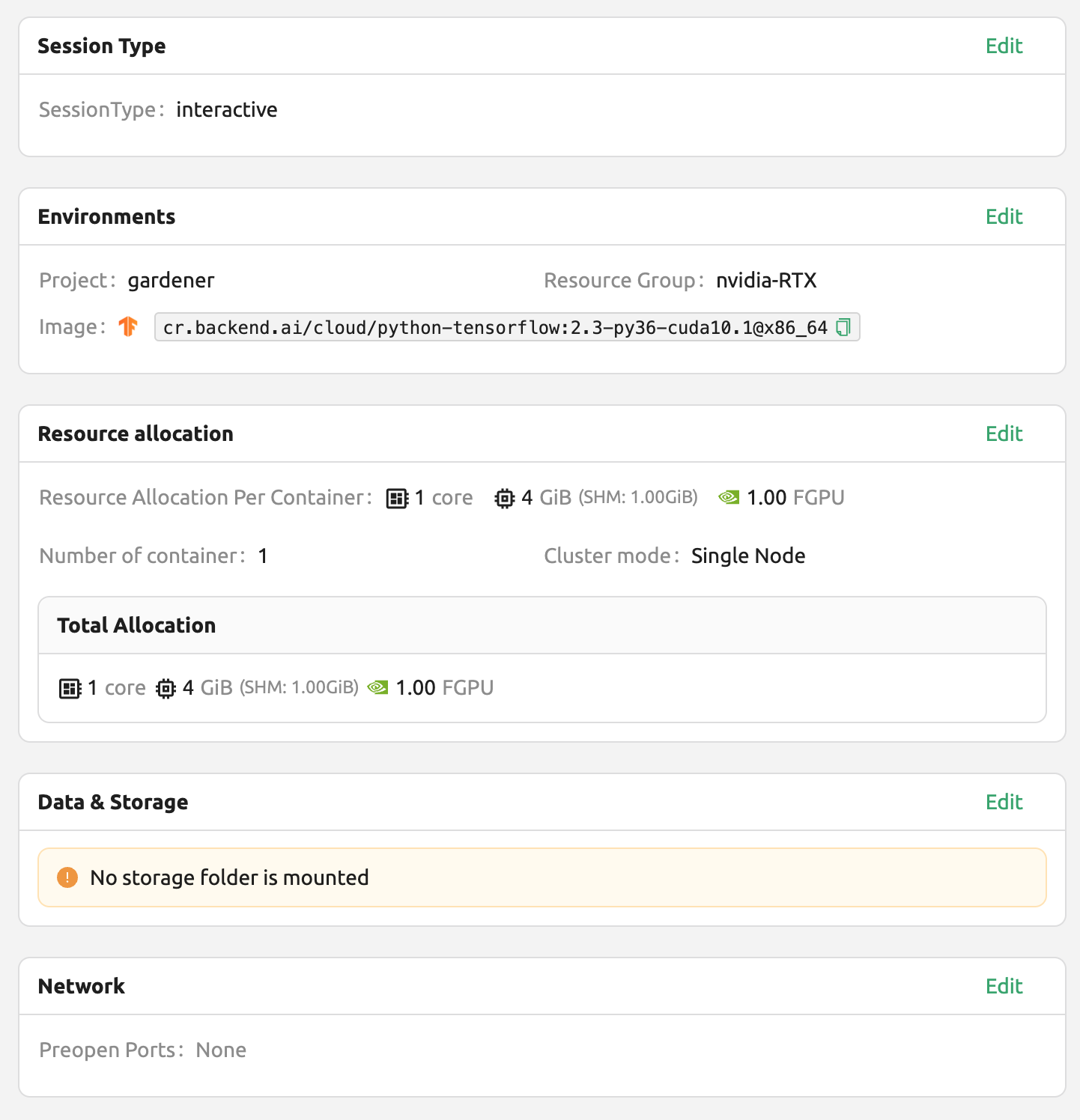
생성된 세션의 웹 터미널을 열고 다음 Python 명령을 실행합니다. TensorFlow 2.3 버전이 실제 설치되어 있음을 확인할 수 있습니다.

이번에는 TensorFlow 1.15 환경을 선택해서 연산 세션을 생성합니다. (자원이 부족한 경우 이전 세션은 삭제합니다)
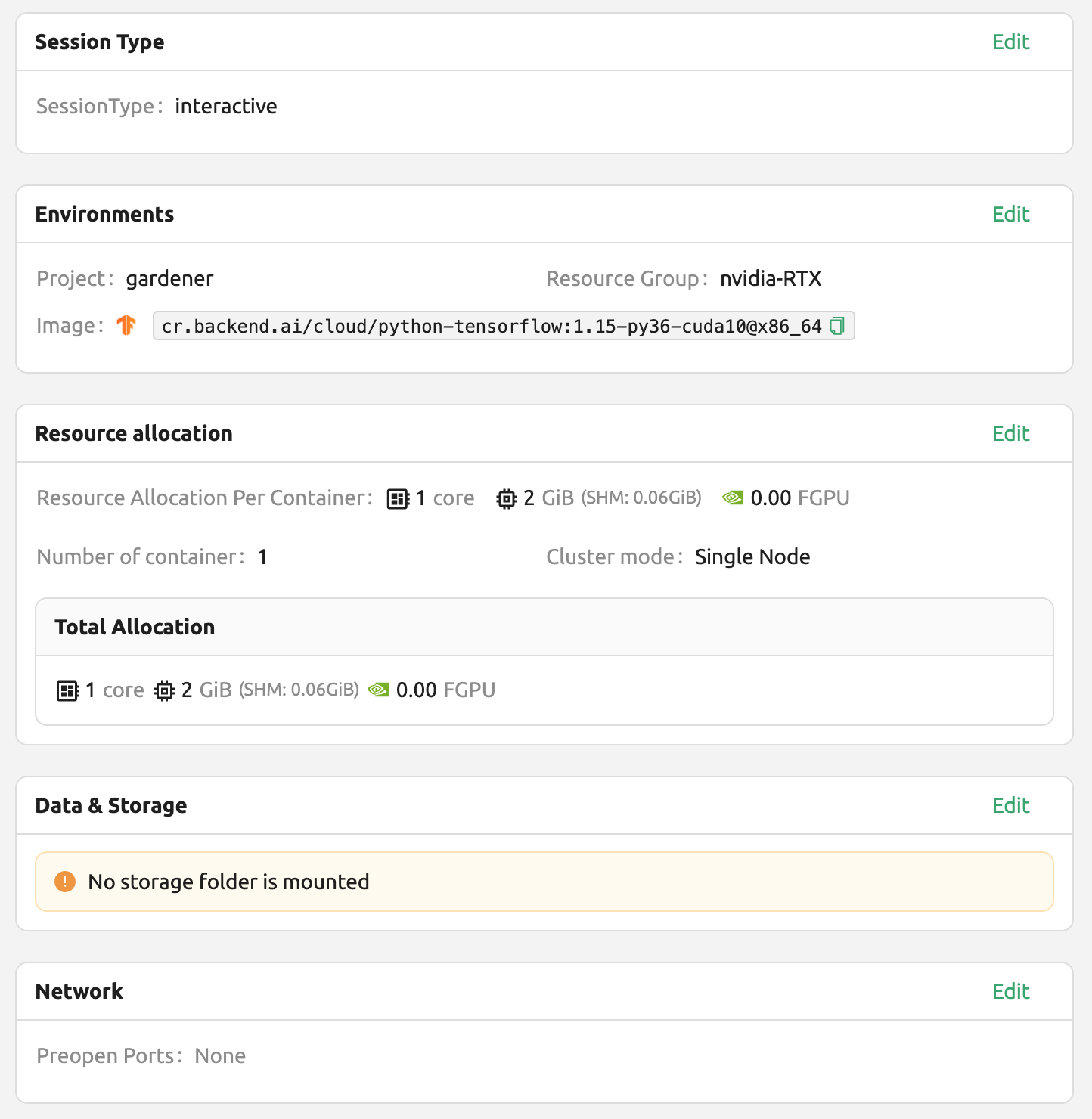
생성된 세션의 웹 터미널을 열고 이전과 동일한 Python 명령을 실행합니다. TensorFlow 1.15(.4) 버전이 실제 설치되어 있음을 확인할 수 있습니다.

마지막으로 PyTorch 1.7 버전을 이용해서 연산 세션을 생성합니다.
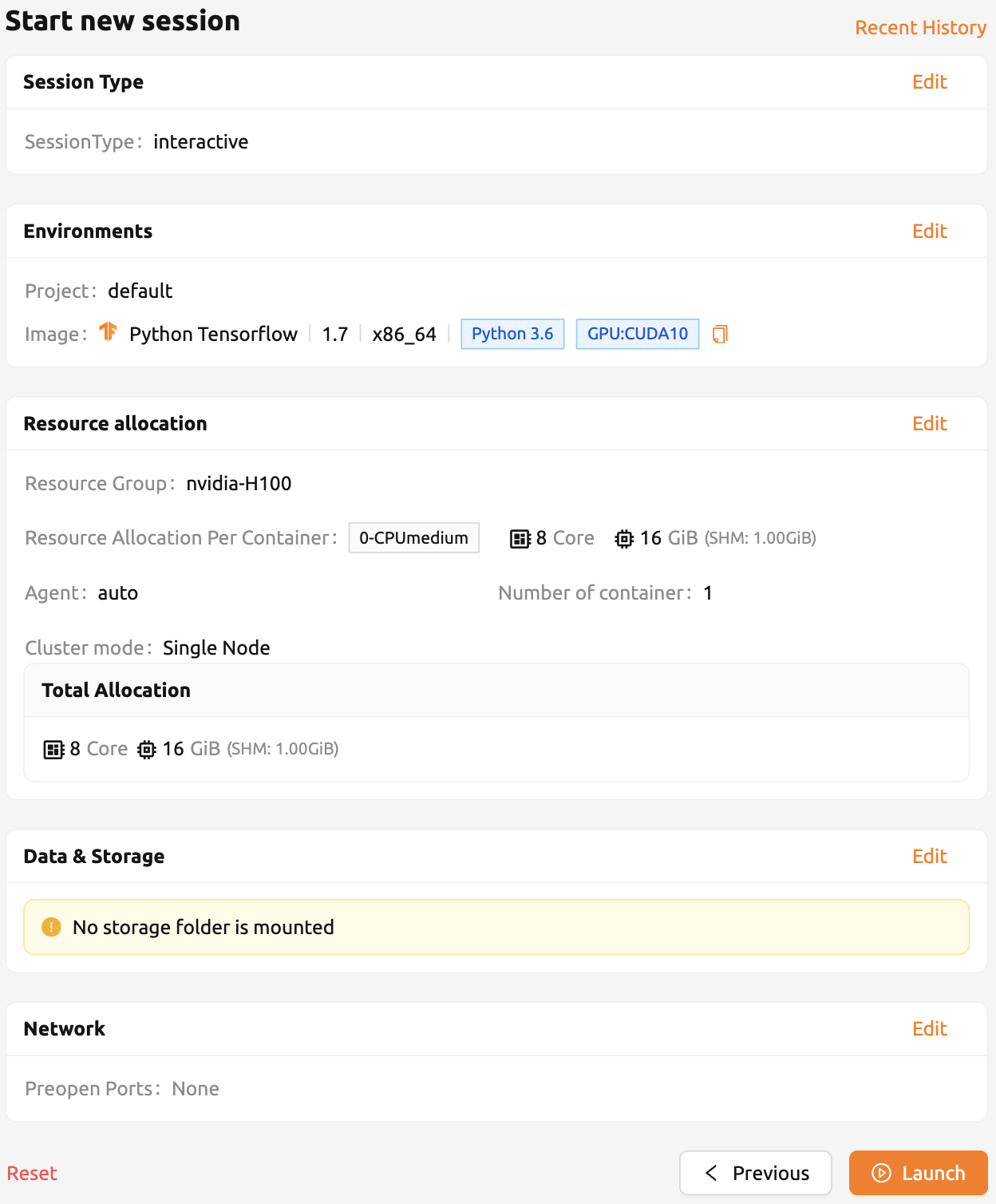
생성된 세션의 웹 터미널을 열고 다음 Python 명령을 실행합니다. PyTorch 1.8 버전이 실제 설치되어 있음을 확인할 수 있습니다.

이처럼, Backend.AI 를 통해 TensorFlow, PyTorch 등 주요 라이브러리의 다양한 버전을 불필요한 설치 노력 없이 활용할 수 있습니다.
실행 중인 연산 세션을 새로운 사용자 이미지로 변환하는 방법
실행 중인 연산 세션(컨테이너) 환경을 새로운 이미지로 변환하고 추후 연산 세션 생성시 사용하고자 하는 경우, 연산 세션 내 환경을 구성한 후 관리자에게 변환 요청을 할 수 있습니다.
먼저, 연산 세션을 준비합니다. 필요한 패키지를 설치하거나 환경을 구성합니다.
참고
apt등과 같은 명령을 통해 OS 패키지를 설치하려면sudo권한이 필요합니다. 플랫폼 제공사의 보안 정책에 따라 연산 세션 내에서sudo사용이 허용되지 않을 수 있습니다.Python 패키지를 pip을 통해 설치하려는 경우, 자동 마운트 폴더 사용을 권장 드립니다. 하지만, 새 이미지 자체에 Python 패키지를 추가하려면
sudo pip install <package-name>과 같이 실행하여 패키지를 홈 디렉토리가 아닌 시스템 디렉토리에 설치하여야 합니다. 연산 세션 내 홈 디렉토리(일반적으로/home/work)는 호스트에서 마운트된 폴더이므로 신규 이미지로 변환할 때 내용이 포함되지 않습니다.연산 세션 환경이 준비되면 관리자에게 이미지로의 변환을 요청합니다. 관리자에게 플랫폼 내 사용자의 이메일과 변환하고자 하는 연산 세션의 이름 또는 ID를 전달해야 합니다.
관리자가 일정 주기로 연산 세션을 이미지로 변환한 후 이미지의 이름과 태그 정보를 전달할 것입니다.
연산 세션 생성 다이얼로그에서 수동으로 이미지 이름을 입력한 후 연산 세션을 생성합니다. 변환된 이미지는 다른 사용자에게 노출되지 않습니다.
새 이미지를 활용해 연산 세션이 정상적으로 실행되어야 합니다.
Backend.AI 서버 설정 가이드
Backend.AI 데몬/서비스 구동을 위해서는 다음과 같은 하드웨어가 필요합니다. 최적 성능을 위해서는 아래 명기된 사양의 두 배 이상 필요합니다.
Manager: 2 cores, 4 GiB memory
Agent: 4 cores, 32 GiB memory, NVIDIA GPU (for GPU workload), > 512 GiB SSD
Webserver: 2 cores, 4 GiB memory
WSProxy: 2 cores, 4 GiB memory
PostgreSQL DB: 2 cores, 4 GiB memory
Redis: 1 core, 2 GiB memory
Etcd: 1 core, 2 GiB memory
각 서비스를 설치하기 전에 사전에 설치되어야 할 주요 의존 호스트 패키지는 다음과 같습니다:
Web-UI: 최신 브라우저를 구동할 수 있는 운영체제 (Windows, Mac OS, Ubuntu 등)
Manager: Python (≥3.8), pyenv/pyenv-virtualenv (≥1.2)
Agent: docker (≥19.03), CUDA/CUDA Toolkit (≥8, 11 recommend), nvidia-docker v2, Python (≥3.8), pyenv/pyenv-virtualenv (≥1.2)
Webserver: Python (≥3.8), pyenv/pyenv-virtualenv (≥1.2)
WSProxy: docker (≥19.03), docker-compose (≥1.24)
PostgreSQL DB: docker (≥19.03), docker-compose (≥1.24)
Redis: docker (≥19.03), docker-compose (≥1.24)
Etcd: docker (≥19.03), docker-compose (≥1.24)
엔터프라이즈 버전의 Backend.AI 서버 데몬은 래블업의 지원팀에서 설치합니다. 초기 설치 후 기본적으로 다음과 같은 자료 및 서비스가 제공됩니다:
DVD 1 장 (Backend.AI 패키지 포함)
사용자 GUI 가이드 매뉴얼
관리자 GUI 가이드 매뉴얼 (엔터프라이즈 고객 전용)
설치 리포트
사용자/관리자 초기 방문 교육 (3-5 시간)
제품의 유지보수 및 지원 정보: 상용 계약에는 기본적으로 엔터프라이즈 버전의 월간/연간 구독 사용료가 포함됩니다. 최초 설치 후 약 2주 간 초기 사용자/관리자 교육 (1-2 회) 및 유무선 상의 고객 지원 서비스가 제공되며, 3-6 개월 간 마이너 릴리즈 업데이터 지원 및 온라인 채널을 통한 고객 지원 서비스가 제공됩니다. 이후 제공되는 유지보수 및 지원 서비스는 계약 조건에 따라 세부 내용이 다를 수 있습니다.
통합 예제
이번 섹션에서는 Backend.AI 플랫폼에서 활용할 수 있는 여러 일반적인 응용 프로그램, 툴킷 및 머신러닝 도구의 예제를 소개하고자 합니다. 각 도구의 기본 사용법과 Backend.AI 환경에서 설정하는 방법, 그리고 간단한 예제를 알려드리겠습니다. 이를 통해 프로젝트에 필요한 도구를 선택하고 활용하는 데 도움이 되기를 바랍니다.
이 가이드에서 다루는 내용은 특정 버전의 프로그램을 기반으로 하고 있으므로, 향후 업데이트에 따라 사용법이 달라질 수 있습니다. 따라서, 이 문서는 참고하시되, 변경 사항을 확인하기 위해서는 최신 공식 문서를 참조하시기를 바랍니다. 이제 Backend.AI에서 사용할 수 있는 강력한 도구들을 하나씩 살펴보겠습니다. 이 섹션이 여러분의 연구 및 개발에 유용한 가이드가 되기를 바랍니다.
MLFlow 사용하기
Backend.AI 에서 제공하는 대부분의 이미지는 MLFlow 와 MLFlow UI 를 빌트인 앱으로 지원합니다. 하지만 실행하기 위해서는 기존 앱과 다르게 몇가지 추가 작업이 필요합니다. 아래의 설명을 따라하면, 로컬 환경에서 MLFlow를 사용하셨던 것처럼 Backend.AI 에서도 파라미터와 결괏값을 추적할 수 있습니다.
참고
이 섹션에서는, 세션을 이미 성공적으로 생성하고, 세션 내 앱을 실행할 수 있는 상태라고 가정합니다. 만약 세션을 생성하고 세션 내에서 앱을 실행하는 방법을 모른다면, 세션 생성하기 를 반드시 먼저 보고 오길 바랍니다.
우선, 콘솔 앱을 먼저 실행한 뒤, 아래의 명령어를 입력하면 mlflow UI 서버가 실행됩니다.
$ mlflow ui --host 0.0.0.0
그 다음, 앱 런처 다이얼로그에서 MLFlow UI 앱을 클릭합니다.
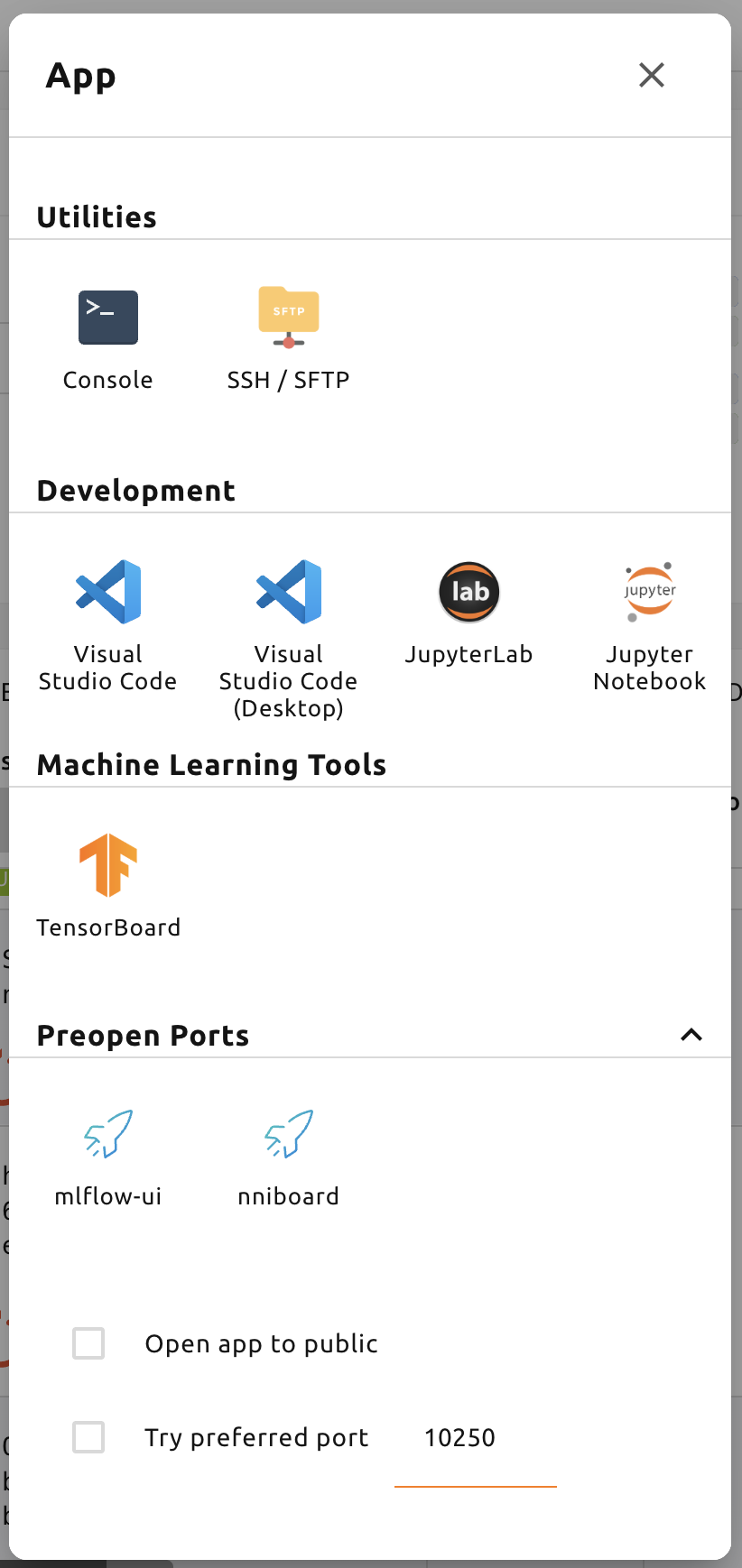
잠시 뒤, MLFlow UI 가 새 창에 띄워집니다.
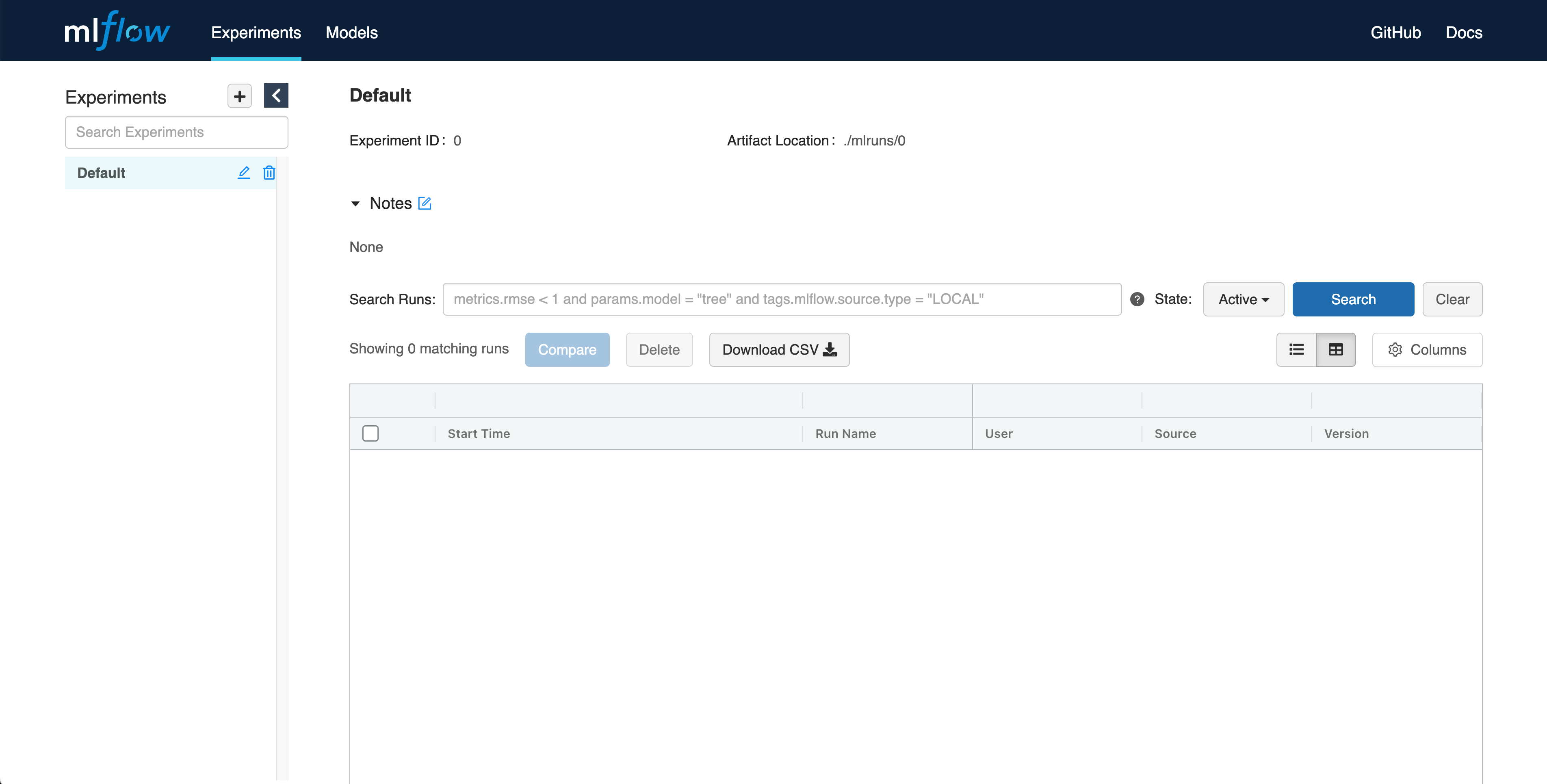
MLFlow 를 사용함으로써, 매번 학습할 때마다 메트릭이나 파라미터 값과 같은 실험 결과를 추적할 수 있습니다. 아주 간단한 예제로 실험 결과를 확인해 봅시다.
$ wget https://raw.githubusercontent.com/mlflow/mlflow/master/examples/sklearn_elasticnet_diabetes/linux/train_diabetes.py $ python train_diabetes.py
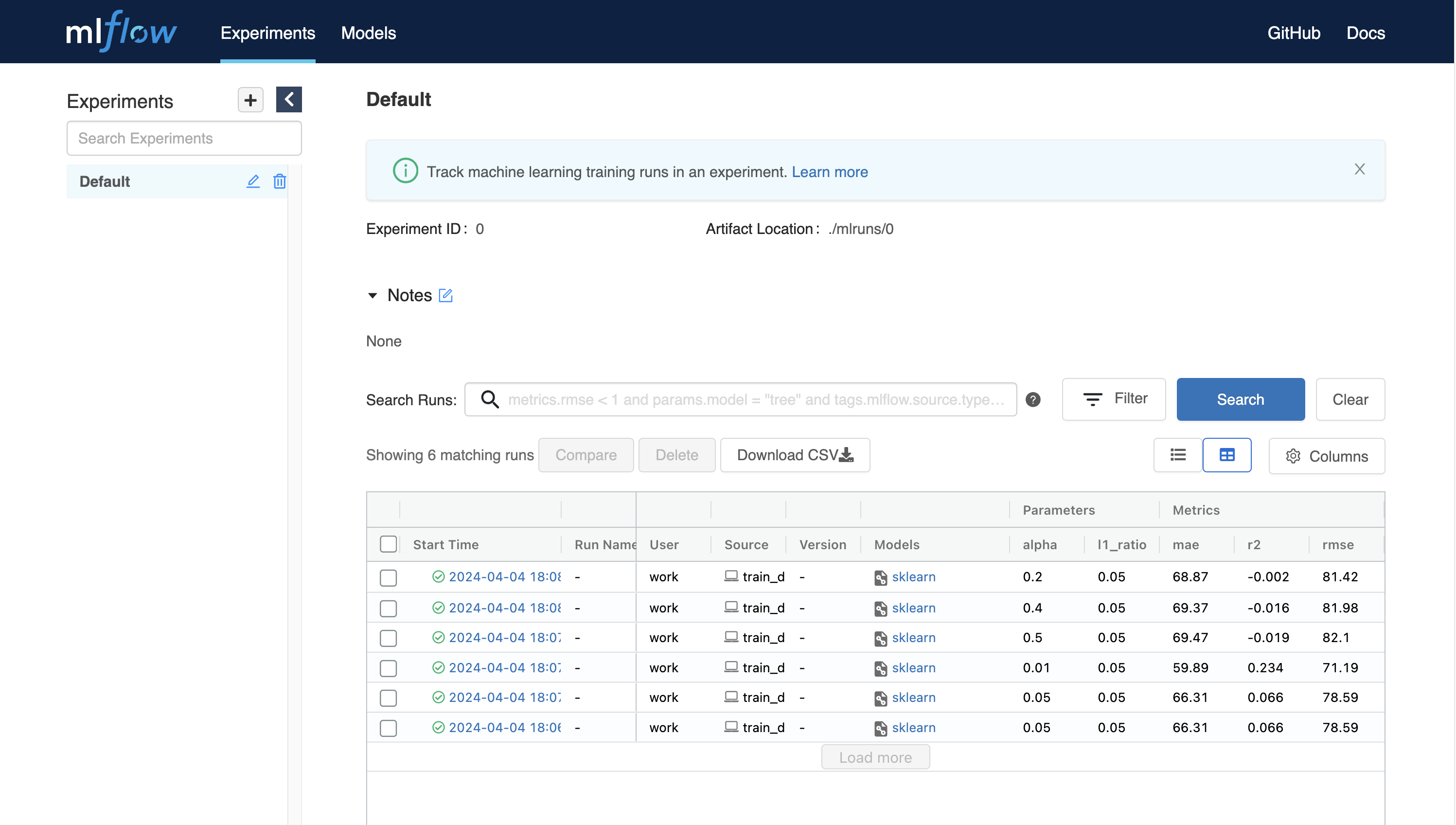
Python 코드를 실행하면, MLFlow에서 결괏값을 확인할 수 있습니다.
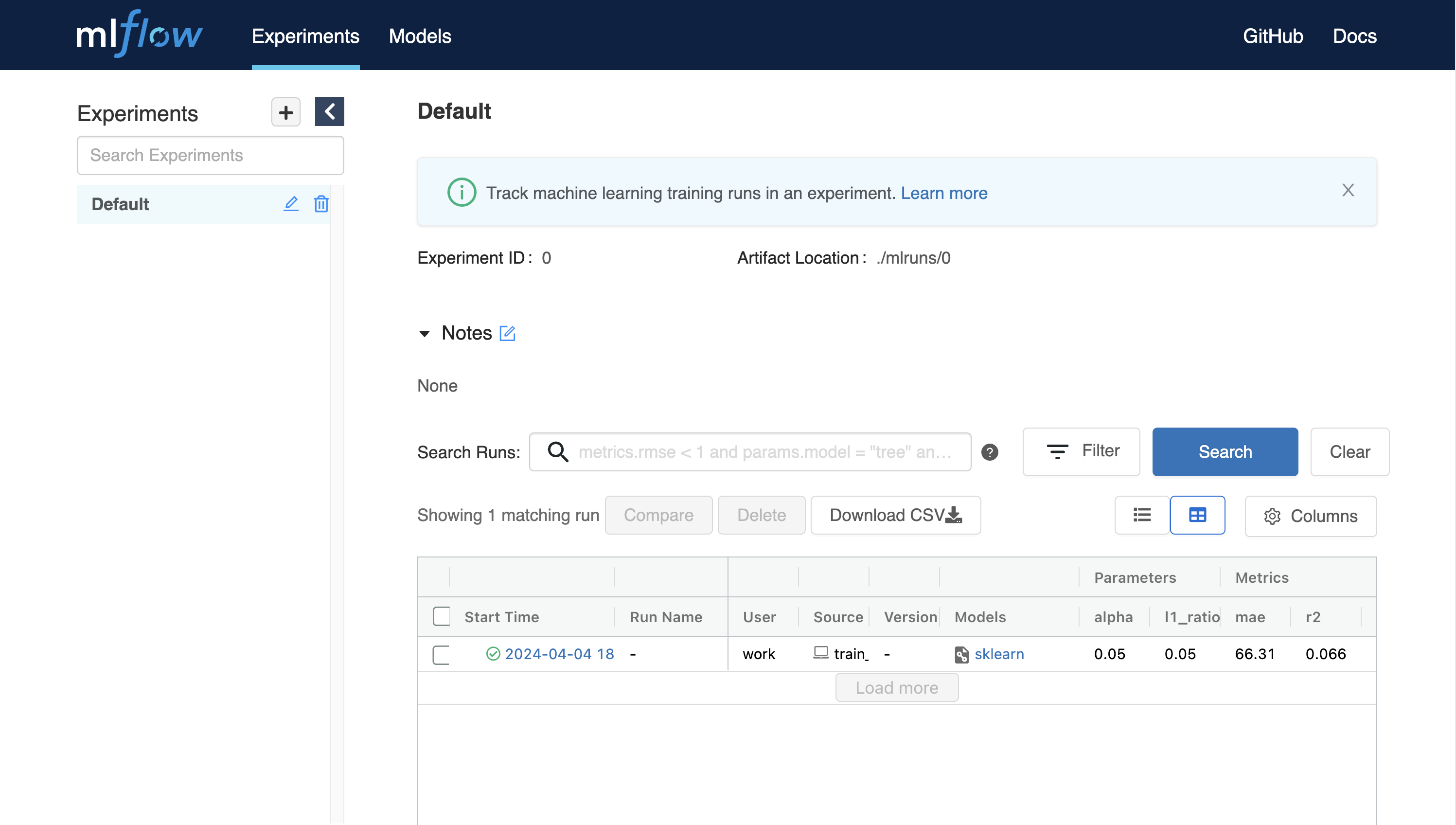
코드 실행시 인자값을 주어 하이퍼파라미터를 직접 설정할 수도 있습니다.
$ python train_diabetes.py 0.2 0.05
몇 번의 학습이 끝나면, 모델 학습 결괏값들을 서로 비교해 볼 수 있습니다.