모델 서빙
모델 서비스
참고
이 기능은 엔터프라이즈 전용 기능입니다.
Backend.AI(백엔드닷에이아이)에서는 모델 학습 단계의 개발 환경 구축 및 자원 관리를 쉽게 해주는 것뿐만 아니라, 모델을 완성한 후 추론 서비스로 배포하고자 할 때에 최종 사용자(예: AI 기반 모바일 앱 및 웹서비스 백엔드 등)가 추론 API를 호출할 수 있게 하는 모델 서비스* 기능을 23.09 버전부터 정식 지원합니다.
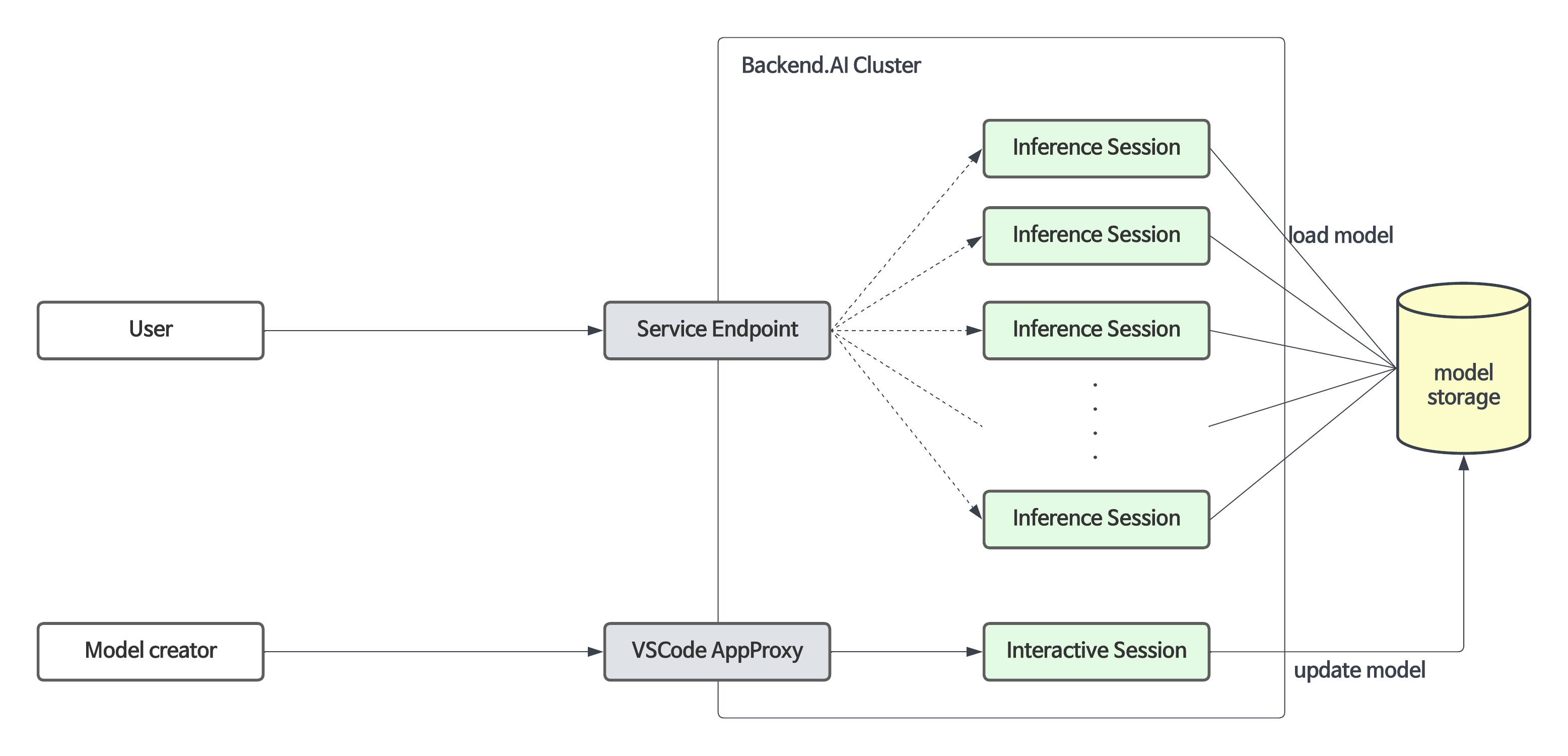
모델 서비스는 기존의 학습용 연산 세션 기능을 확장하여, 자동화된 유지·보수 및 스케일링을 가능하게 하고 프로덕션 서비스를 위한 영구적인 포트 및 엔드포인트 주소 매핑을 제공합니다. 개발자나 관리자가 연산 세션을 수동으로 생성·삭제할 필요 없이 모델 서비스에 필요한 스케일링 파라미터를 지정해 주기만 하면 됩니다.
23.03 및 이전 버전에서 모델 서비스를 구성하는 방법과 한계
모델 서빙에 특화된 모델 서비스 기능은 23.09에서 정식 지원하지만, 그 이전 버전들에서도 제한적인 모델 서비스 기능을 활용할 수 있습니다.
예를 들어, 23.03 버전에서는 다음과 같은 방법으로 학습용 연산 세션을 변용하여 모델 서비스를 구성할 수 있습니다:
세션 생성시 사전 개방 포트를 추가해서 모델 서빙을 위한 세션 내 실행중인 서버 포트와 매핑하도록 설정(사전 개방 포트 사용법에 대한 설명은 세션 생성하기 전에 사전 개방 포트를 추가하는 방법 을 참고하십시오.)
앱을 외부에 공개체크하여 사전 개방된 포트에 매핑된 서비스를 외부로 공개하도록 설정(앱을 외부에 공개 에 대한 자세한 설명은 앱을 외부에 공개 를 참고하십시오.)
대신 23.03 버전에서는 다음과 같은 제한 사항들이 있습니다:
세션이 외부 요인(유휴 시간 만료, 시스템 오류 등)으로 종료될 경우 자동으로 복구되지 않습니다.
세션을 새로 실행할 때마다 앱 포트가 변경됩니다.
세션을 반복적으로 재실행할 경우, 유휴 포트가 고갈될 수 있습니다.
23.09의 정식 모델 서비스 기능은 위와 같은 제한 사항들을 해결합니다. 따라서 23.09 버전부터는 가급적 모델 서빙 메뉴를 통해 모델 서비스를 생성·관리하는 것이 좋습니다. 사전 개방 포트 기능을 활용하는 방법은 개발 및 테스트 과정에서만 사용하는 것을 권장합니다.
모델 서비스를 사용하기 위한 단계 안내
모델 서비스를 사용하기 위해서는 크게 아래와 같은 단계를 따라야 합니다:
모델 정의 파일 생성하기
모델 정의 파일을 모델 타입 폴더에 업로드하기
모델 서비스 생성하기/유효성 검사하기
(모델 서비스가 공개되지 않은 경우) 토큰 발급하기
(엔드 유저 전용) 모델 서비스에 대응하는 엔드포인트에 접속하여 서비스 확인하기
(필요한 경우) 모델 서비스 수정하기
(필요한 경우) 모델 서비스 종료하기
모델 정의 파일 생성하기
참고
24.03버전부터는 모델 정의 파일명을 지정할 수 있습니다. 단, 모델 정의 파일 경로를 입력하는 란에 아무것도 입력하지 않을 경우, 시스템에서는 모델 파일명을
model-definition.yml또는model-definition.yaml로 간주하게 됩니다.
모델 정의 파일은 Backend.AI 시스템이 추론용 세션을 자동으로 시작, 초기화하고 필요에 따라 스케일링할 때 필요한 설정 정보를 담고 있는 파일입니다. 이 파일을 추론 서비스 엔진을 담고 있는 컨테이너 이미지와는 독립적으로 모델 타입 폴더에 저장합니다. 이를 통해 모델을 실행하는 엔진이 다양한 모델을 필요에 따라 바꿔가며 서비스할 수 있도록 하며, 모델이 변경될 때마다 컨테이너 이미지를 새로 빌드 및 배포하지 않아도 되도록 해줍니다. 네트워크 스토리지에서 직접 모델 정의와 모델 데이터를 불러오므로, 자동 스케일링 시 배포 과정을 더 단순화 및 효율화할 수 있습니다.
모델 정의 파일은 다음과 같은 형식을 따릅니다:
models:
- name: "simple-http-server"
model_path: "/models"
service:
start_command:
- python
- -m
- http.server
- --directory
- /home/work
- "8000"
port: 8000
health_check:
path: /
interval: 10.0
max_retries: 10
max_wait_time: 15.0
expected_status_code: 200
initial_delay: 60.0
모델 정의 파일에 대한 키-값 설명
참고
Fields without "(Required)" mark are optional.
name(필수): 모델 명을 정의합니다.model_path(필수): 모델이 정의된 경로를 지정합니다.service: 서비스할 파일(명령어 스크립트, 코드 포함)에 대한 정보를 정리해두는 항목입니다.pre_start_actions:start_command항목 내 명령어 이전에 실행되어야 할 명령어 또는 액션을 정리해두는 항목입니다.start_command(필수): 모델 서빙시 실행할 명령어를 지정합니다. 문자열 또는 문자열 목록으로 지정할 수 있습니다.port(필수): 모델 서비스의 컨테이너 포트 (예:8000,8080).health_check: 모델 서비스의 주기적인 상태 모니터링 설정입니다. 설정 시, 시스템이 서비스의 응답 여부를 자동으로 확인하고 비정상 인스턴스를 트래픽 라우팅에서 제외합니다.path(필수): 상태 확인 요청을 보낼 HTTP 엔드포인트 경로 (예:/health,/v1/health).interval(기본값:10.0): 연속 상태 확인 사이의 간격(초).max_retries(기본값:10): 서비스를UNHEALTHY로 표시하기 전까지 허용되는 연속 실패 횟수. 이 임계값을 초과할 때까지 서비스는 계속 트래픽을 수신합니다.max_wait_time(기본값:15.0): 각 상태 확인 HTTP 요청의 타임아웃(초). 이 시간 내에 응답이 없으면 확인 실패로 간주합니다.expected_status_code(기본값:200): 정상 응답을 나타내는 HTTP 상태 코드. 일반적인 값:200(OK),204(No Content).initial_delay(기본값:60.0): 컨테이너 생성 후 상태 확인을 시작하기 전 대기 시간(초). 모델 로딩, GPU 초기화, 서비스 워밍업 시간을 확보합니다. 대형 모델의 경우 더 높은 값을 설정하세요 (예: 70B+ LLM의 경우300.0).
참고
상태 확인은 app proxy coordinator의 백그라운드 태스크에 의해 트리거되며,
health_check_timer_interval(기본값:30초) 주기로 실행됩니다. 모델의interval설정이 이보다 짧은 경우, coordinator의 주기에 따라 수행됩니다.아래 예제들은
health_check_timer_interval≤interval설정을 가정합니다.
상태 확인 동작 이해하기
상태 확인 시스템은 개별 모델 서비스 컨테이너를 모니터링하고, 상태에 따라 트래픽 라우팅을 자동으로 관리합니다.
Container Created
│
▼
┌─────────────────────────────────┐
│ Wait for initial_delay (60s) │ ← Model loading, GPU init, warmup
│ Status: DEGRADED │
│ No health checks during this │
└─────────────────────────────────┘
│
▼
Start Health Check Cycle
│
▼
┌─────────────────────────────────┐
│ Every interval (10s): │
│ HTTP GET → path ("/health") │
└─────────────────────────────────┘
│
▼
Wait up to max_wait_time (15s)
│
┌──────────┴──────────┐
▼ ▼
Response Timeout/Error
│ │
▼ │
Status == │
expected? │
│ │
┌┴┐ │
▼ ▼ │
Y N │
│ │ │
│ └─────────┬──────────┘
│ ▼
│ Consecutive
│ failures +1
│ │
▼ ▼
HEALTHY Failures > max_retries?
(reset │
failures) ┌─────┴─────┐
▼ ▼
Yes No
│ │
▼ ▼
UNHEALTHY Keep current
(removed status
from traffic
internally)
참고
내부 상태 (트래픽 라우팅에 사용됨)는 사용자 인터페이스에 표시되는 상태와 즉시 동기화되지 않을 수 있습니다.
UNHEALTHY까지 소요 시간:
초기 시작 시:
initial_delay + interval × (max_retries + 1)기본값 예시: 60 + 10 × 11 = 170초 (약 3분)
운영 중 (정상 상태 이후):
interval × (max_retries + 1)기본값 예시: 10 × 11 = 110초 (약 2분)
Backend.AI 모델 서빙에서 지원하는 서비스 액션 안내
write_file: 입력받은 파일 명으로 파일을 생성, 내용을 추가하는 액션입니다.mode값에 아무것도 적지 않을 경우 기본 접근 권한은644입니다.arg/filename: 파일명을 적습니다.body: 파일에 추가할 내용을 적습니다.mode: 파일의 접근 권한을 적습니다.append: 파일에 내용 덮어쓰기/덧붙이기 설정을True/False로 적습니다.
write_tempfile: 임시파일명(확장자는.py)을 갖는 파일을 생성, 내용을 추가하는 액션입니다.mode값에 아무것도 적지 않을 경우 기본 접근 권한은644입니다.body: 파일에 추가할 내용을 적습니다.mode: 파일의 접근 권한을 적습니다.
run_command: 명령어를 실행한 결과(오류포함)를 아래와 같은 형태로 반환하게 됩니다.(out: 명령어 실행 결과,err: 명령어 실행 중 오류 발생시 출력되는 오류 메시지)args/command: 실행할 명령어를 배열형태로 적습니다. (e.g.python3 -m http.server 8080명령어는 ["python3", "-m", "http.server", "8080"])
mkdir: 입력한 경로에 따라 디렉토리를 생성하는 액션입니다.args/path: 디렉토리를 만들 경로를 지정합니다.
log: 입력한 메시지에 따라 로그를 출력하는 액션입니다.args/message: 로그에 표시할 메시지를 적습니다.debug: 디버그 모드인 경우True, 아닌 경우False로 적습니다.
모델 정의 파일을 모델 타입 폴더에 업로드하기
모델 정의 파일(model-definition.yml) 을 모델 타입 폴더에 업로드하기 위해서는 가상 폴더를 생성해야 합니다. 이 때, 가상폴더 생성시 타입은 일반 이 아닌 모델 타입으로 선택하여 생성합니다. 생성하는 방법은 데이터 페이지의 Storage 폴더 생성 부분을 참고하십시오.

폴더를 생성한 뒤, 데이터 페이지에서 '모델' 탭을 선택, 방금 생성한 모델 타입 폴더 아이콘을 클릭하여 폴더 탐색기를 엽니다. 이후 모델 정의 파일을 업로드합니다. 폴더 탐색기에 대한 자세한 사용 방법은 폴더 탐색기 를 확인하세요.


모델 서비스 생성하기/유효성 검사하기
모델 정의 파일까지 모델 타입의 가상 폴더에 모두 업로드하였다면, 본격적으로 모델 서비스를 생성할 준비가 된 것입니다.
모델 서빙 페이지에서 '서비스 시작' 버튼을 클릭하면, 서비스 생성에 필요한 설정을 입력하는 페이지로 이동합니다.

먼저, 서비스 이름을 입력합니다. 각 항목에 대한 자세한 설명은 아래 내용을 참고하십시오.
앱을 외부에 공개: 모델 서비스 생성 후 서비스하고자 하는 서버에 별도의 토큰이 없이도 접근할 수 있도록 하는 옵션. 기본적으로 비활성화 되어 있음.
마운트할 모델 스토리지 폴더: 모델 정의 파일이 들어있는 마운트 할 모델 폴더를 선택.
인퍼런스 런타임 종류: 모델 서비스 타입을 네가지로 나눔: 'vLLM', 'NVIDIA NIM', '미리 정의된 이미지 명령어', '커스텀'.

예를 들어 'vLLM'이나 'NVIDIA NIM', 또는 '미리 정의된 이미지 명령어' 를 모델 서비스의 런타임 배리언트로 선택한다면, 'model-definition' 파일을 마운트할 모델 폴더에 업로드할 필요가 없습니다. 그 대신, 별도의 환경변수 를 설정해야 할 수도 있습니다. 더 자세한 정보를 확인하려면, 모델 배리언트: 쉽게 서빙하는 다양한 모델 서비스 포스팅을 확인하시기 바랍니다.

모델 폴더 마운트할 경로: 서비스의 라우팅에 대응하는 세션에 마우트 될 모델 스토리지 경로에 별칭 추가. 기본값은
/models.모델 정의 파일 경로: 모델 스토리지 경로에 있는 모델 정의 파일을 정하는 옵션으로, 기본 값은
model-definition.yaml.추가 마운트: 세션과 마찬가지로, 서비스에 폴더를 추가로 마운트할 수 있음. 단, 모델 폴더는 추가 마운트가 불가능하고, 일반/데이터 사용 모드의 폴더만 마운트할 수 있음.

그리고, 복제본 수와 이미지 환경, 자원 그룹을 선택합니다. 자원 그룹은 모델 서비스에 할당될 수 있는 자원의 집합입니다.
복제본 수: 해당 설정은 현재 서비스에 대해 유지할 라우팅 세션 수를 결정하는 기준이 됨. 만약 해당 설정값을 변경하면, 매니저가 기존에 실행되고 있는 복제본의 개수를 참조하여 새로운 복제본을 생성하거나, 실행중인 세션을 종료할 수 있음.
실행 환경 / 버전: 모델 서비스에서 서비스 전용 서버의 실행 환경을 설정, 현재는 서비스 내 라우팅이 여러 개여도 단일 실행 환경으로만 실행되도록 지원하고 있음. ( 추후 업데이트 예정 )

자원 프리셋: 모델 서비스에서 할당하고자 하는 자원량을 선택할 수 있음. 자원에는 CPU, RAM, 그리고 GPU로 알려져있는 AI 가속기가 해당.

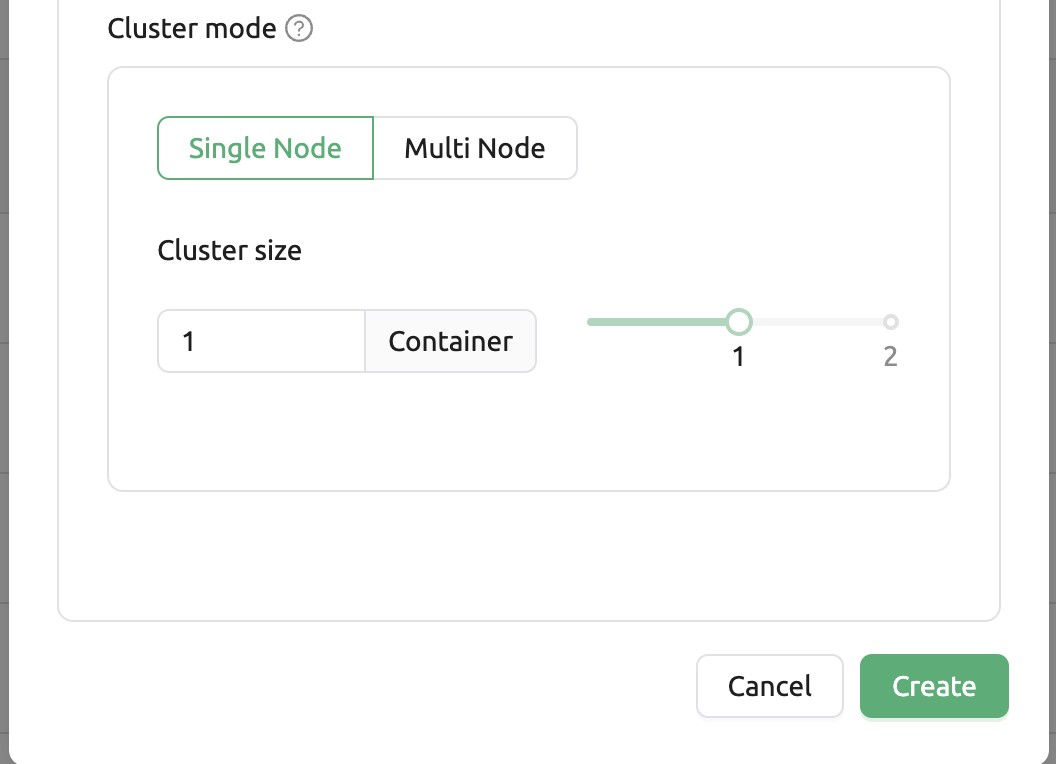
단일 노드: 세션을 실행할 때에 관리 노드와 워커 노드들이 하나의 물리 노드 또는 가상 머신에 배치되는 경우.
다중 노드: 세션을 실행할 때 하나의 관리 노드와 하나 이상의 워커 노드가 여러 물리 노드 또는 가상 머신에 나누어 배치되는 경우.
환경 변수: 이 섹션에서는, 모델 서비스를 시작할 때 설정되는 환경 변수를 설정할 수 있음. 런타임 배리언트를 사용해서 모델 서비스를 생성할 때 유용함. 몇몇 런타임 배리언트는 시작 전 환경 변수 설정이 필요함.
모델 서비스를 생성하기 전, Backend.AI에서는 성공적으로 실행이 가능한지 아닌지(실행중 발생하는 어떤 에러로 인해 실행이 불가능한 경우) 를 체크하는 유효성 검사를 지원합니다. 서비스 런쳐의 좌측 하단에 위치한 Validate 버튼을 클릭하면 유효성 검사 이벤트를 확인하는 팝업창이 새로 뜨게 됩니다. 이 팝업 창에서, 여러분은 컨테이너 로그로 상태를 확인할 수 있습니다. 결괏값이 Finished 로 뜨게 되면, 유효성 검사가 끝난 것을 의미합니다.

참고
Finished 결괏값이 실행이 성공적으로 종료되었음을 의미하지는 않습니다. 그 대신, 컨테이너 로그를 반드시 확인하시기 바랍니다.
모델 서비스 생성에 실패한 경우
만일 모델 서비스의 상태가 UNHEALTHY 로 되어 있는 경우, 모델 서비스를 정상적으로 실행할 수 없는 상태라고 볼 수 있습니다.
생성이 안 되는 이유 및 해결법은 대개 다음과 같습니다:
모델 서비스 생성 시 너무 적은 양의 자원을 라우팅에 할당한 경우
해결법: 해당 서비스를 우선 종료하고, 이전 설정보다 많은, 충분한 양의 자원을 할당하도록 설정하여 서비스를 재생성합니다.
모델 정의 파일(
model-definition.yml) 의 형식이 잘못된 경우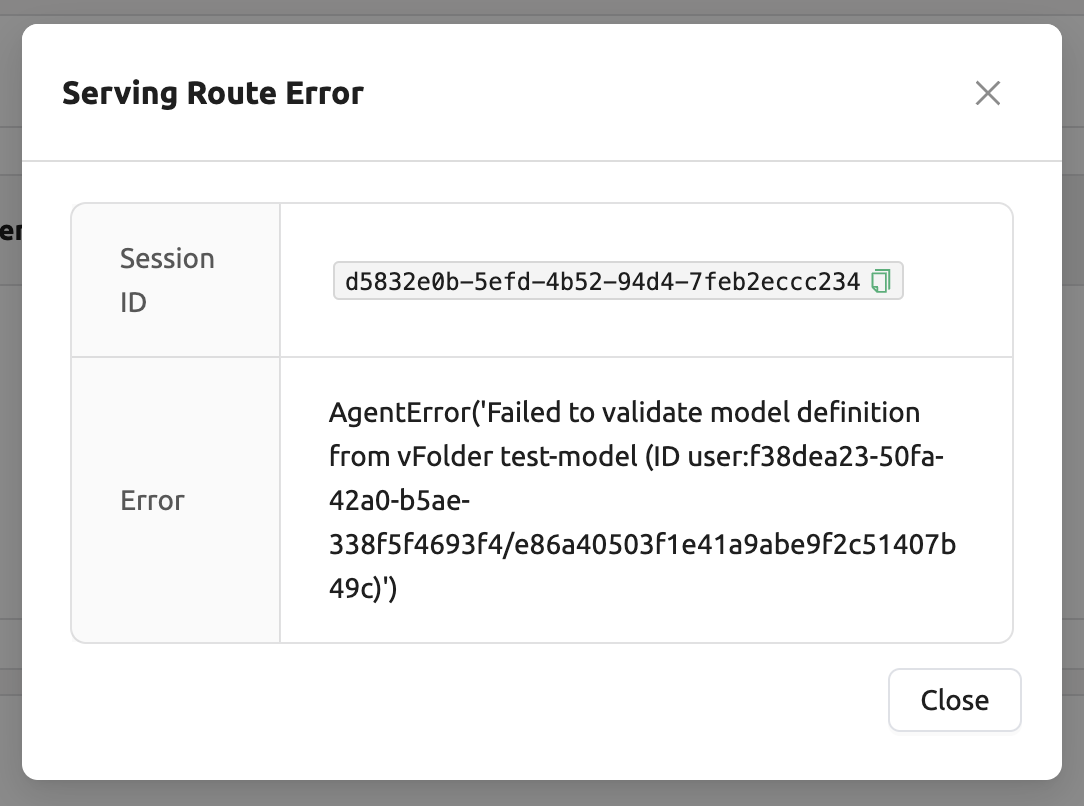
해결법: 모델 정의 파일 형식 을 확인하고, 키-값이 잘못된 경우, 수정하여 저장된 경로에 업로드해 덮어쓰기합니다. 이후 아래와 같이
오류 지우고 재시도버튼을 클릭하여 라우트 정보에 쌓인 에러를 모두 삭제하고, 재시작해 모델 서비스의 라우팅이 정상적으로 동작할 수 있도록 합니다.

오토스케일링 규칙
실행 중인 서비스에 대해 오토스케일링 규칙을 설정할 수 있습니다. 설정된 규칙에 따라 서비스 사용량이 적을 때는 복제본 수를 줄여 자원을 절약할 수 있고, 사용량이 많을 때는 복제본 수를 늘려 요청 지연이나 실패를 방지할 수 있습니다.

'규칙 추가' 버튼을 클릭하면 규칙을 추가할 수 있는 모달이 나타나며, 각 항목의 의미는 다음과 같습니다:
규칙을 정의합니다. 규칙의 적용 범위에 맞게 스케일 업 또는 스케일 다운 중 하나를 선택합니다.
메트릭 소스: 메트릭이 수집될 소스를 선택합니다. Inference Framework 또는 Kernel 중에서 선택할 수 있습니다.
Inference Framework: 모든 복제본에 대해 계산된 평균값입니다. 모든 앱 프록시 인스턴스가 추론 메트릭을 보고하는 경우에만 지원됩니다.
Kernel: 해당 엔드포인트를 구성하는 모든 커널의 값에 대해 계산된 평균값입니다.
조건: 오토스케일링 규칙이 작동하는 조건을 설정합니다.
메트릭: 비교에 사용될 메트릭의 이름입니다. 실행 환경에서 지원하는 메트릭이라면 자유롭게 입력할 수 있습니다.
비교 방식: 실시간 메트릭 값이 임계값과 비교되는 기준을 정의합니다.
LESS_THAN: 현재 메트릭 값이 설정된 기준값보다 낮아지면 해당 규칙이 실행됩니다.
LESS_THAN_OR_EQUAL: 현재 메트릭 값이 설정된 기준값보다 낮아지거나 같을 경우 해당 규칙이 실행됩니다.
GREATER_THAN: 현재 메트릭 값이 설정된 기준값을 초과하면 해당 규칙이 실행됩니다.
GREATER_THAN_OR_EQUAL: 현재 메트릭 값이 설정된 기준값을 초과하거나 같을 경우 해당 규칙이 실행됩니다.
기준값: 스케일링 조건이 충족되는지를 판단하기 위한 기준값입니다.
단게 크기: 규칙이 실행될 때 변경될 복제본 수입니다. 양수 또는 음수로 설정할 수 있으며, 음수로 설정된 경우 복제본 수가 감소합니다.
최대/최소 복제본 수: 해당 엔드포인트의 복제본 수에 대한 최대값/최소값을 설정합니다. 계산된 복제본 수가 최대값을 초과하거나 최소값 미만이 되는 경우, 규칙은 실행되지 않습니다.
쿨다운 시간(초): 규칙이 한 번 실행된 후, 일정 시간(초) 동안 동일한 규칙이 다시 적용되지 않도록 하는 대기 시간입니다.

토큰 발급하기
모델 서비스를 성공적으로 실행한 경우, 상태는 HEALTHY 에 속하게 됩니다. 이 경우 모델 서비스 탭에서 해당하는 엔드포인트 명을 클릭해 모델 서비스의 상세 정보를 확인할 수 있습니다. 이후 모델 서비스의 라우팅 정보에서 서비스 엔드포인트를 확인할 수 있는데, 이 엔드포인트는 서비스 생성시 외부에 공개할 수 있는 'Open to Public' 값이 활성화 된 경우, 엔드포인트가 공개되어 별도의 토큰이 없이도 최종 엔드 유저가 엔드포인트에 접근할 수 있습니다. 하지만 비활성화 된 경우는 토큰 발급 후 토큰을 아래와 같은 형태로 추가해서 서비스가 정상적으로 실행되고 있는지 확인할 수 있습니다.

라우팅 정보의 생성된 토큰 목록 우측에 있는 'Generate Token' 버튼을 클릭합니다. 이후 토큰 생성을 위한 모달이 뜨면, 만료일을 입력합니다.

이후 발급되는 토큰은 생성된 토큰 목록에 추가됩니다. 토큰 항목의 '복사' 버튼을 클릭하여 토큰을 복사하고, 아래와 같은 키의 값으로 추가하면 됩니다.

키 |
값 |
|---|---|
Content-Type |
application/json |
Authorization |
BackendAI |
(엔드 유저 전용) 모델 서비스에 대응하는 엔드포인트에 접속하여 서비스 확인하기
모델 서빙이 완료되려면 실제 최종 엔드 유저에게 모델 서비스가 실행되고 있는 서버에 접근할 수 있도록 정보를 공유하여야 합니다. 이 때 서비스 생성시 Open to Public 값이 활성화한 경우라면 라우팅 정보 페이지의 서비스 엔드포인트 값을 공유하면 됩니다. 만일 비활성화 한 채로 서비스를 생성한 경우라면 서비스 엔드포인트 값과 앞서 생성한 토큰 값을 공유하면 됩니다.
curl 명령어를 사용해서 모델 서빙 엔드포인트에 보내는 요청이 제대로 동작하는 지 아닌지 확인할 수 있습니다.
$ export API_TOKEN="<token>"
$ curl -H "Content-Type: application/json" -X GET \
$ -H "Authorization: BackendAI $API_TOKEN" \
$ <model-service-endpoint>
경고
기본적으로 엔드 유저는 엔드포인트에 접근이 가능한 네트워크 망에 있어야 합니다. 만일 폐쇄망에서 서비스를 생성한 경우, 폐쇄망 내 접근이 가능한 엔드 유저만 접근이 가능합니다.
거대 언어 모델 (LLM) 사용하기
LLM(Large Language Model) 모델 서비스를 생성했다면, 실시간으로 LLM을 사용해 볼 수 있습니다. 서비스 엔드포인트 열에 있는 'LLM 채팅 테스트' 버튼을 클릭하여 테스트를 수행할 수 있습니다.

버튼을 클릭하면 채팅 페이지로 이동되며, 사용자가 생성한 모델이 자동으로 선택됩니다. 채팅 페이지에 제공된 채팅 인터페이스를 통해 LLM 모델을 테스트할 수 있습니다. 채팅 기능에 대한 자세한 내용은 채팅 페이지 를 참고하세요.

API에 연결하는 데 문제가 발생하는 경우, 채팅 페이지에서 모델 설정을 수동으로 구성할 수 있는 옵션이 표시됩니다. 모델을 사용하려면 다음 정보를 입력해야 합니다.
baseURL (선택사항): 모델이 위치한 서버의 기본 URL. 해당 URL에는 버전 정보가 포함되어 있어야 합니다. 예를 들어, OpenAI API를 사용하는 경우, https://api.openai.com/v1 을 입력해야 합니다.
Token (선택사항): 모델 서비스에 접근하기 위한 인증 키. 토큰은 Backend.AI 뿐만 아니라 다양한 서비스에서 생성할 수 있습니다. 토큰 생성 방법은 서비스에 따라 다를 수 있습니다. 자세한 내용은 해당 서비스의 안내를 참조하십시오. Backend.AI에서 생성한 서비스를 사용하는 경우, 토큰 생성 방법은 토큰 발급하기 섹션을 참조하십시오.

모델 서비스 수정하기
모델 서비스를 수정하기 위해선, 제어 탭의 설정 아이콘을 클릭합니다. 수정 모달은 모델 서비스를 시작하는 모달과 형태가 동일하며, 이전에 입력했던 필드들이 적용되어 있습니다. 원하는 필드를 수정하고 확인 버튼을 클릭하게 되면, 변경 사항이 적용됩니다.

모델 서비스 종료하기
모델 서비스는 주기적으로 스케줄러를 실행하여, 원하는 세션 수와 실제 대응하는 라우팅 수가 원하는 세션 수에 맞춰지도록 스케줄링합니다. 다만, 이 경우 Backend.AI 스케줄러에 부하가 가는 것은 불가피합니다. 따라서 모델 서비스를 더 이상 사용하지 않는 경우라면, 모델 서비스를 종료하는 것이 좋습니다. 모델 서비스를 종료하려면, 제어 탭에서 휴지통 아이콘을 클릭합니다. 이후 모델 서비스를 종료하는 것이 맞는지 확인하는 모달이 뜨게 됩니다. 삭제 버튼을 누를 경우 모델 서비스는 종료됩니다. 종료된 모델 서비스의 경우 모델 서비스 목록에서 제거됩니다.
